
The Legal Design Lab has a new addition: Metin Eskili has joined us as our new full-stack developer. He will be working with us on access to justice applications that we’ll be developing and researching in-house (in-lab).
Our first big project is in machine learning. This is an exploratory project, that is feeding into a much larger Access to Justice/AI effort that we expect to take several years. We are seeing what is possible now, in training a machine to be able to recognize different families of legal issues, or even very fine-grained specific issues.
The small initial task we’re focused on is being able to correctly classify official, court or legal aid self-help resources. We want to be able to say what exact legal issue these different guides, forms, FAQs, and timelines refer to. This will help us in our overall project, when we aim to connect people more directly to the best legal resource to fit their particular legal issue.
Scraping and Labelling
Metin has built a scraper to go through all of the court and statewide legal self-help websites. It is gathering up all of the guides, forms, FAQs, decision trees and other materials that have been published by courts and legal aid groups, to help people without lawyers get through court processes.
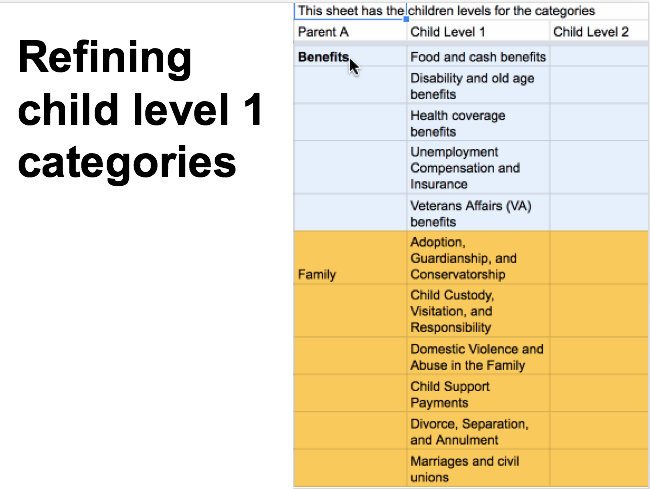
All those parts of web pages are making a corpus of ‘official legal self-help guides’, which I am labelling. I am starting with high-level tags of family, housing, immigration, money, work, and education. Then we will get to more fine-grained categories, like specific types of divorce, eviction, visas, harassment, etc.
Starting to predict high-level families of issues
At the same time as we are doing this labelling, we are training our machine learning model — we are using the library Spacy and the tool Prodigy — to then be able to predict which family of issues or specific issue is present in a given paragraph, sentence, or webpage.

We are focusing our initial training on Family Law. To do this, I have been training the model initially on what ‘seed terms’ belong to family law. This means providing a first set of about 20 terms to the machine that would indicate a family law issue might be present. Then the machine returns to me a long list of other terms that it thinks might also indicate family law. I check or x off those terms, to better train it on ‘seed terms’.
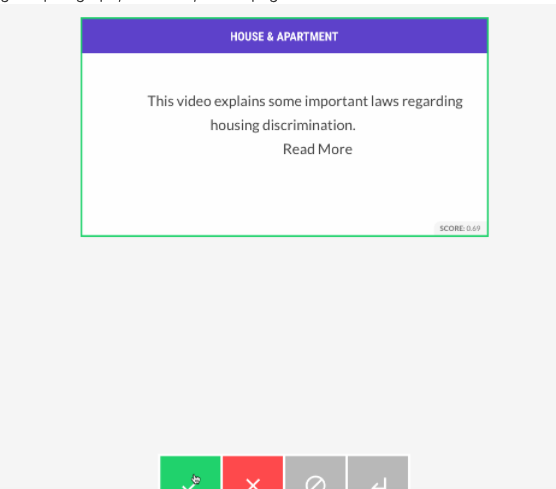
After we get that list of about 500 checked or x-ed seed terms, we feed that back to the model. It looks over our ‘corpus’ of legal self-help materials, and tries to classify them. It makes a prediction of which of the self-help materials likely have to do with family law or not. Then it presents that back to me, and I go through and check or x off which actually are related to family law or not.

Check in: can the machine see the family law yet?
After I finish checking or x-ing off about 1500 different entries, to tell the machine whether the self-help information is about Family Law or not, then we check back in with the model. We want to see if it is able to correctly predict whether a given statement indicates a Family Law issue is present or not. This helps us see how much more training we need to do.
Here is our latest check-in with our model. We enter in a statement, and ask the model to tell us what the percentage likelihood that a family law issue is present or not.

You can see that it’s very sure — 99% sure — on most of the family law issues — when it sees a statement around dissolution, falling out of love with a spouse, adopting a child, or enrolling a grandkid in school.
Non-family law issues — around landlords, or around human trafficking – the model is pretty good at saying conclusively: there is around 0% chance this is a family law issue.
The Gray Zone of in-between legal issues
We are also interested gray-zone issues, like getting immigration visas for family members. Lawyers would say it is an immigration law issue, and not a family law issue. But many lay people we talk to would look under ‘family’ to try to find out resources. The model gives it an 81% prediction as a family law issue. If we just ask it about getting a green card, it goes down to 69% prediction of family law.
Another gray-zone is around health care. When we ask the model about getting health care for our kid, it gives us a 96% prediction of a family law issue. Lawyers would probably be saying — go to the health law section, you shouldn’t be in family law. But again, lay people we are interviewing are saying if it involves caring for kids, they would be looking for it to be around family law, and would be phrasing sentences that concentrate on family relationships and situations.
These gray-zone issues (around immigration paths for family members, special education plans for your kids, health care for your kids, debt related to child support) — all point us to to why lawyers’ categories and segmentation of problems don’t work for people.
This is why another part of our big project is to move away from having people be able to navigate lawyers’ categories. Rather than direct people to websites where they have to figure out where lawyers put the answers they want — we want to be able to label the resources and people’s questions with specific issue codes, so that we can better match them.
More to come
As we explore more what impactful applications of AI we can develop for access to justice, we will be doing a lot more work, with some very exciting partnerships in the pipeline. This exploratory work is helping us educate ourselves about what might be possible, and how we can apply new classifiers or ontologies in meaningful ways.